I previously posted “but don’t forget that over-automating can lead to reduced visibility“. Machines do what we tell them (to a fault), how do we retain some control?
Example – At Demisto, when you ask for access to our help-center, the email is processed by a SOAR playbook to validate the request, manage access, and respond to the user, like self-service.
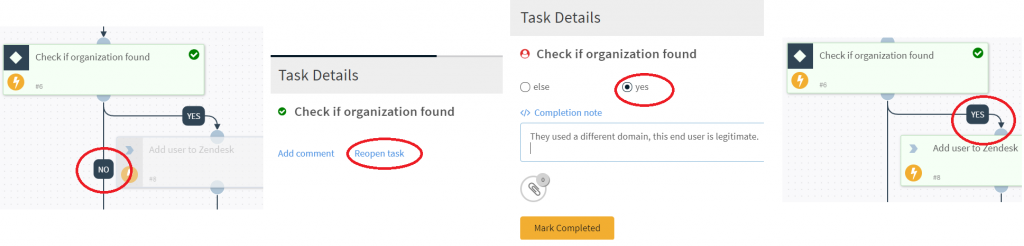
However recently it took a wrong turn so I had to open and take control and override our usual logic. This was easy as each incident (which the automation belongs to) is tracked like case management, so we simply “re-open”, open up the playbook to find the issue, and correct it.
So what best practise can we utilise to keep control over SOAR?
Human Checks – Before any critical steps (e.g. pushing IP to firewall) you might want to ask a human analyst to verify (either using ticket management, email/slack question, or using the Mobile App)
Playbook Design – Many playbooks have forks based upon automated decisions. Consider the chain of events in a ticket if is restarted from a certain point taking a different action. Do any original steps have to be undone? A good design allows users to quickly make changes and walk away.
Human Notifications – If anything is seen slightly odd (too much data in a reply) then continue a human analyst of the observation with a direct link “click here to see the playbook in operation”
Summary Page – All key data and decisions should be in the tickets summary page, so any analyst/team leader having a quick view can see the key points of ticket (e.g. User not found resulting in playbook taking a specific course of action)
Andy