How many vendors at RSA 2019 magically now do SOAR… I lost count (and I’m reeeally good at counting).
Unfortunately this trickled down into people minds, and I hear “but my endpoint will do SOAR” (sorry, I’m not picking on endpoint specifically).
So let’s analyse the reality of ‘we added SOAR’
Source Agnostic
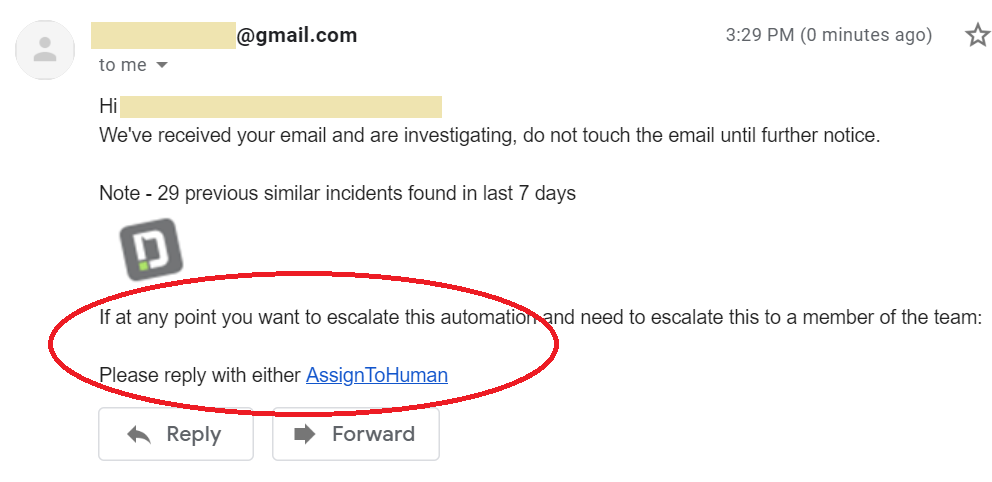
SOAR should be agnostic for where an alert/alarm/trigger comes from.
Example – If your Endpoint is also your SOAR platform, is it still as functional when the alert is generated in Amazon GuardDuty alerts, or from Jira tickets?
Integration Count
Ok great your ‘me too’ platform can integrate with MISP, ePO, ActiveDirectory, Cuckoo. But who has those exact technologies? Your toolsets will change and grow over time.
Example – A SOAR platform has hundreds on integrations. Anything less means a gap, and you will still do all the work yourself.
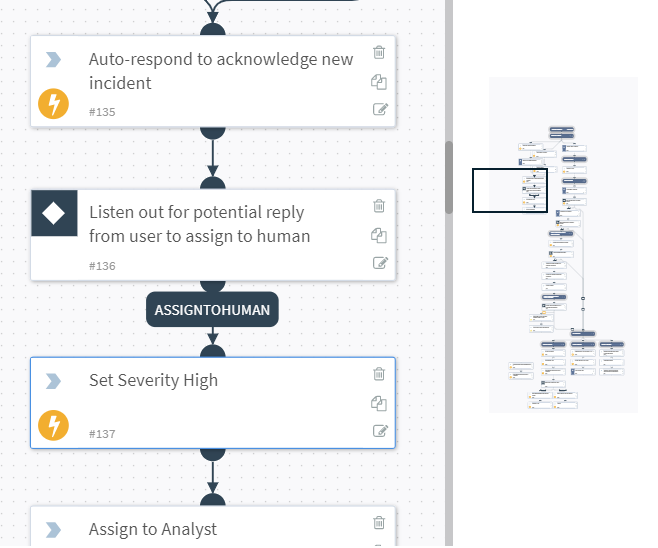
Workflow
If solution ‘XYZ’ has workflow built in, is it designed around the functionality specific to that product?
Example – Would a Deception technology with SOAR understand and support workflow needed for Vulnerability management?
Reporting
So if your “me too” SOAR solution…
- can’t trigger from multiple sources
- only integrates with 30% if your security stack
- can’t handle half the workflows
…how can you get any meaningful reporting out of it?
Summary
I’ve heard of vendors saying ‘we do SOAR’ when in reality they just have integrations, and maybe you can change the order, but that’s not SOAR.
And I’ve not even covered: customisation, load balancing, RBAC, multi tenancy, threat intelligence tracking, custom IOC definitions, collaborative work spaces, and dozens more.
Andy