Last year, I proposed, and she said yes. The best day ever!
But later the same year ‘we’ agreed I was taking responsibility for the invites.
Part 1 of this series – Data, tickets and QR Code Part 2 of this series – Printed invites for end users Part 3 of this series – Reporting and dashboards
Interactive web frontend to using API for all the information for guests
Interactive RSVP
This will require each person use a unique code/password
Though creating online accounts is too complicated for Great Aunt Betty…
…so use a minimal URL including a unique code
And for mobile device convenience, a QR Image with the code baked in
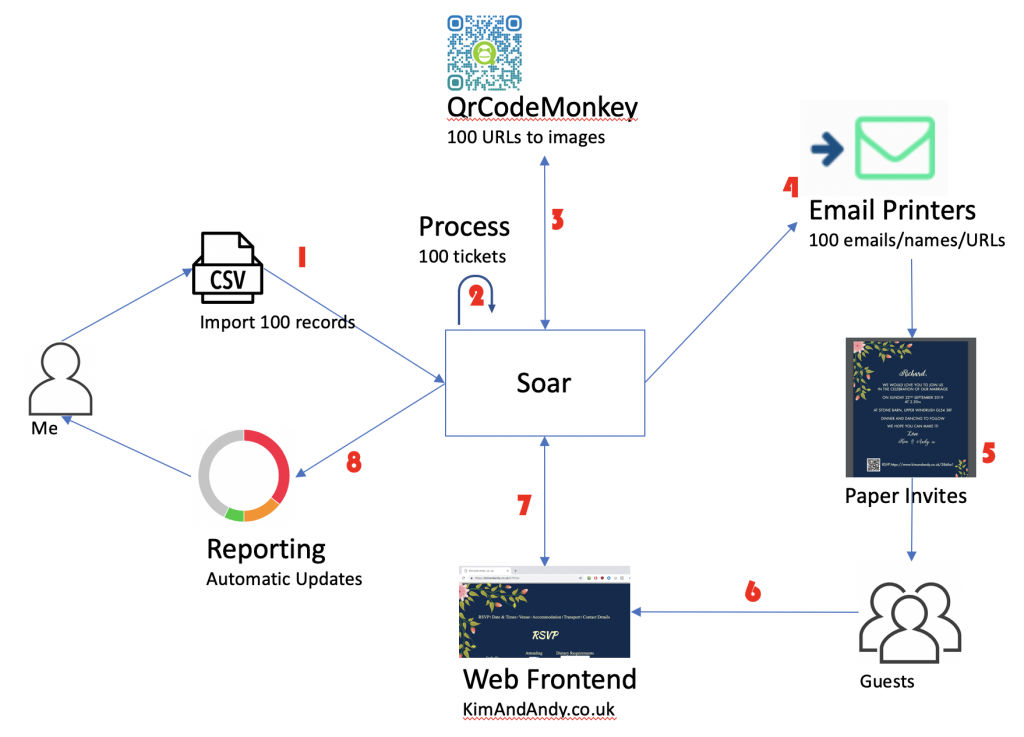
With the needs identified I mocked up this workflow.
So here in part 1 of this 3 part series, are all the steps along with images!
Create a Demisto instance specifically for my Wedding
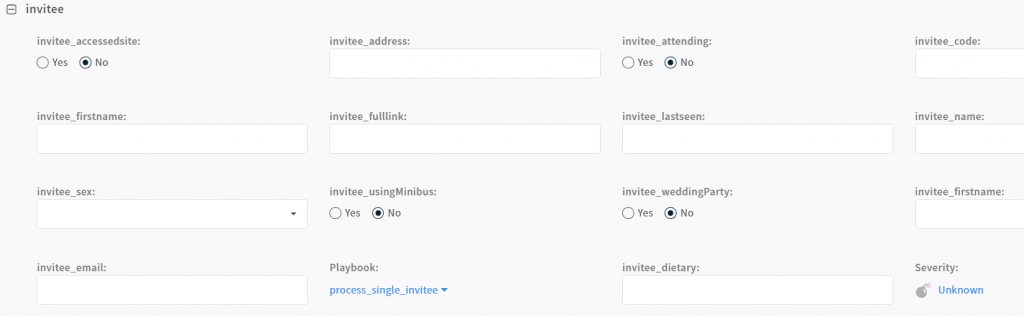
Design the schema for “guest” and map these to a “new ticket” form
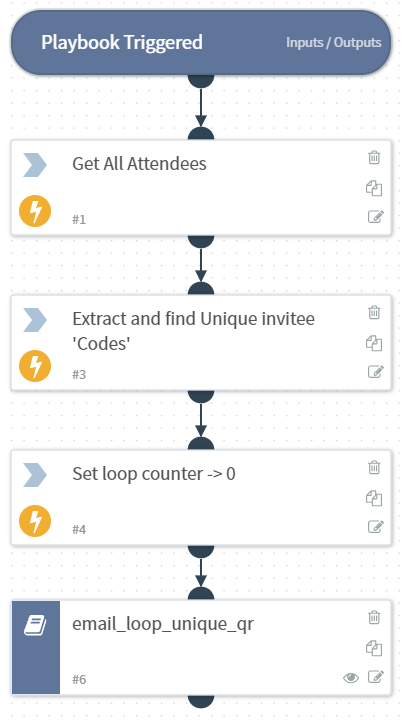
Time to add all the guests (originally I started off typing these in manually, but I realised I’m lazy so I created a CSV, and then wrote a playbook to import and process each row)
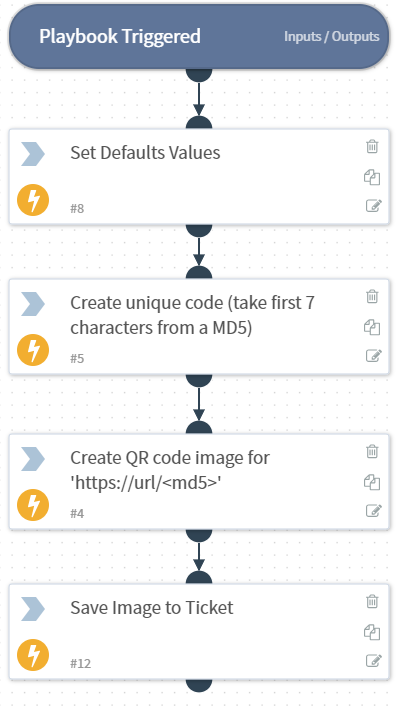
The above playbook executes once creating dozens of tickets, one for each invitee. Each ticket then runs a playbook to prepare and process itself
The QR Code task calls the QRCodeMonkey integration. Here we give it a string “https://__url__/__uniquecode__” and it returns an image
Here is a QR Code generated by the automation (dummy data)
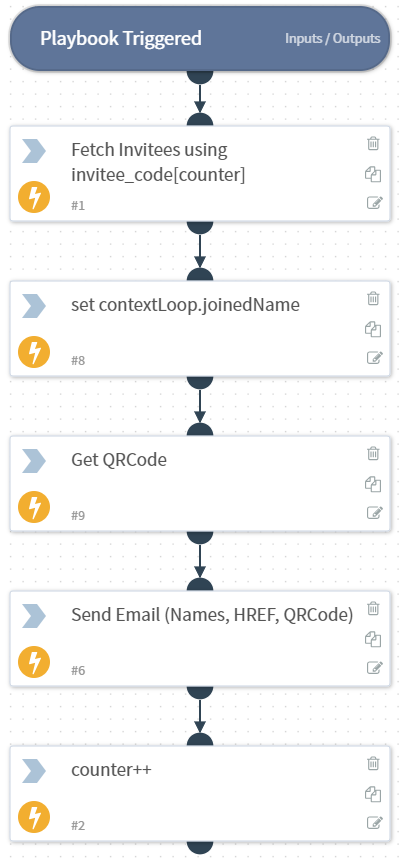
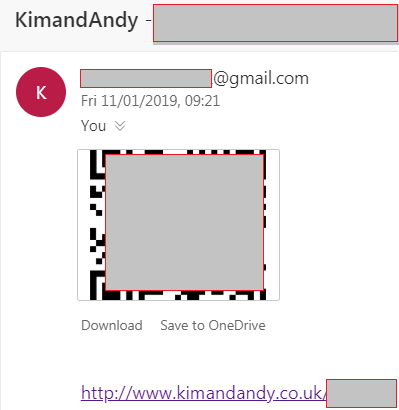
When I was happy the data looked right. I wrote a playbook to loop through every invitee and send an email to the printing company that contained the invitee names, address, unique URL and QRCode image as an attachment
Playbook which loops with counter
The loop
And here is the output, lots emails, each specific to a specific invitee.
Here is the real benefit. Should we make any changes to the URL, email, QRCode, or individual invitee we can make 1 simple change and then execute the playbooks again. All data is regenerated, reprocessed and automatically emailed out… all with 1 click !
I’m starting to see a few of these, and I love it !!
True it’s a vague question to answer or measure, but as a customer the best way to be heard is at RFI stage. Vendors take note of every single RFI “non compliance”.
I was recently asked about unit testing, using a SOAR platform to routinely test its own playbooks for errors. I hope to implement each of these in the future as a POC, I’ll update with links when this happens.
Breaking it down I see three uses cases here.
In this article ticket and incident are used interchangeably
1: Unit testing a particular task
Individual tasks can be tested in isolation away from the full production playbook, we define specific input for each test and we know the expected output. Two ways to test a Task
i) check the task output (or context location) to see if the data exists/has length/has correct values ii) for tasks with no output, check immediately after a task whether Exit Status is 0 or 1 (similar to Linux)
For this we need
The task to test
Immediately after we check ExitStatus
A task to validate output
This process is wrapped in a parent playbook #A that loops, each time passing in new test criteria
Playbook #A summarises the results and updates itself for future reporting
2: Unit Testing a Subplaybook
Whilst not technically mandatory, sub playbooks will have input/output defined (otherwise what’s the point in them?). We can call this subplaybook in our Test playbook, specifying the input, then watching the Subplaybook for it’s formal output.
For this we need
The subplaybook to test (with input and output configured) #B
A parent playbook #C that calls #B with new input and tests each round of output
#C is called from playbook #D that defines the array of test data
3: Unit Testing a ‘parent’ playbook
As a ‘parent’ playbook is never called from another playbook it’s input will be passed at ticket creation (meaning one ticket per test unlike above where 1 ticket can iterate through many values in a loop). Likewise at the end data is not passed out anywhere so we have to query the ticket to test execution.
To test, depending on the playbook, we might consider:
Initiate the incident, wait 2 minutes and check for status to see whether the playbook finished, or if it’s stuck (Error or human input required)
Like above we can check some ticket fields for expected output
When the ticket has ended we check the execution run time for any anomalies
For this we need
The playbook to test #E
A parent playbook #F that can create other tickets setting input parameters
#F is called from playbook #G that defines the array of test data and is scheduled to run once every day.
Hopefully in the not too distant future I’ll get these working and uploaded here for reference.
I’ve asked myself this many times, when is a automation a good solution? When is it not?
Let’s look analyse how an analyst might perform a Phishing query:
Copy paste the email into a new ticket
Inform the end user their request was acknowledged
Extract the URLs, copy paste them into Threat Intel platforms
Extract the IPs, copy paste them into Threat Intel Platforms
Get the file hash, copy paste them into Threat Intel Platforms
Copy the file, upload to a sandbox, paste results back into the ticket
Check if the URL in the email was similar to your corporate domain
If not malicious, email the end user and close the ticket
If malicious then we do more….
Email the end user saying “yes”, update the ticket
Update severity to “high”
Query SIEM, query other mailboxes for known IOC
Let’s analyse the workflow:
Most of this is simply copy pasting
The data structure is always the same
The process is always the same (and it’s extremely repetitive and boring!)
Analyst is logged on and is interacting with half a dozen different interfaces (leads to eye fatigue)
All the involved solutions (ticket systems, threat intel, SIEM, mail… ) all have APIs.
Let’s now analyse a potential workflow for insider data theft:
Analyse evidence to identify the Threat Actor
Identify scope of breach across network
Attempt to identify the intent
Inform the relevant parties (HR, Legal, etc), maybe include the Law
When appropriate, lock the user out of the appropriate system
Analyse potential losses, whether that’s IP theft, PII theft, financial, reputational and act accordingly
etc
Let’s analyse the workflow:
This is a process that happens infrequently (hopefully)
Whilst this process is standardised at a conceptual level, which can be represented in a playbook for process definition…
…every run through will be completely different
You will often interact with different data, in different systems
Original notifications to teams will be the same, but every communication will be completely unique
Humans don’t have API
Intent, reputation and loss need dedicated human input to determine.
To be clear, there is a great value in formally mapping this second scenario to a playbook, but I wouldn’t call it a primary use case for SOAR.
Summary
So what tasks are no-brainers for a SOAR platform? I believe it’s a process that…
…is always the ~same
…has many steps
…takes time to do
…is boring!
…can access/utilise API
I originally listed “…works across multiple platforms”, and whilst that’s fascinating to see in motion, I’ve taken it out because even SOAR enriching and empowering a single isolated technology can be a great solution for the right usecase.