Editor’s note: A massive thankyou to Patrick Bayle for today’s guest post on using a SOAR playbook to handle major incident management comms.
When does a use case be classified as something other than a use case?
When posing the question to customers I engage with, the responses are fairly typical from a small subset of common challenges focused around security incident management. Some typical examples as follows:
- triaging SIEM alerts
- malware investigations
- Phishing
And so on. It’s hard sometimes not to feel like I am a terrible game show host seeking audience participation but I would much rather this than hear crickets!
I am nothing if not prepared for such engagements and having first hand experience helps when focusing attention to the matters that would bring MOST value to the SOC and one such example is common but rarely thought of in the realms of incident handling.
In an industry plagued with three-letter acronyms for stuff this one appears to have slipped through the net, for now at least. I have heard it described as “Major Incident Management” (MIM) or “Critical Incident Handling” (CIH). Neither the acronym nor naming convention matters in truth, yet this is one challenge that can have serious repercussions to a business not automated. Pertaining specifically to MIM/ CIH, the SOCs goal is to:
Ensure a consistent methodology is applied during a major/ critical incident and regular communications occur during the investigation of said incident.
If you’ve ever had to firefight (metaphorically or other) then you will know that communication is often automatically placed to the bottom of the list as the priority is to fight fire (obviously). A SOC analyst has to diagnose and mitigate a threat as quickly as possible and naturally all attention is on performing this duty. Updating management slows the response and detracts from the task at hand so quite simply automation is the only option.
How about this: a playbook that runs on a schedule and sends an email with a predefined format to a distribution list in the event of an incident that exists that matches “critical”. That would solve the problem of communication whilst ensuring that the SOC can do their thing and put the fire out as quickly as possible! Well look no further as we have a playbook for that:

The playbook logic is very simple: If there is no critical incident, then no email is sent; if there is a critical incident then the playbook generates the report at a schedule defined by the business (in my case the requirement was to update management at least every thirty minutes but this does vary). Here’s the filter on the search incident task:

And the mail received, with an attachment and a small amount of text with the incident numbers (customisable of course):

The attachment (funnily enough, also easily customised) is designed for management’s perusal. A separate email with much more detail can also be sent to the SOC manager… but this is probably unnecessary as they should be using the default XSOAR dashboard that shows them this 🙂
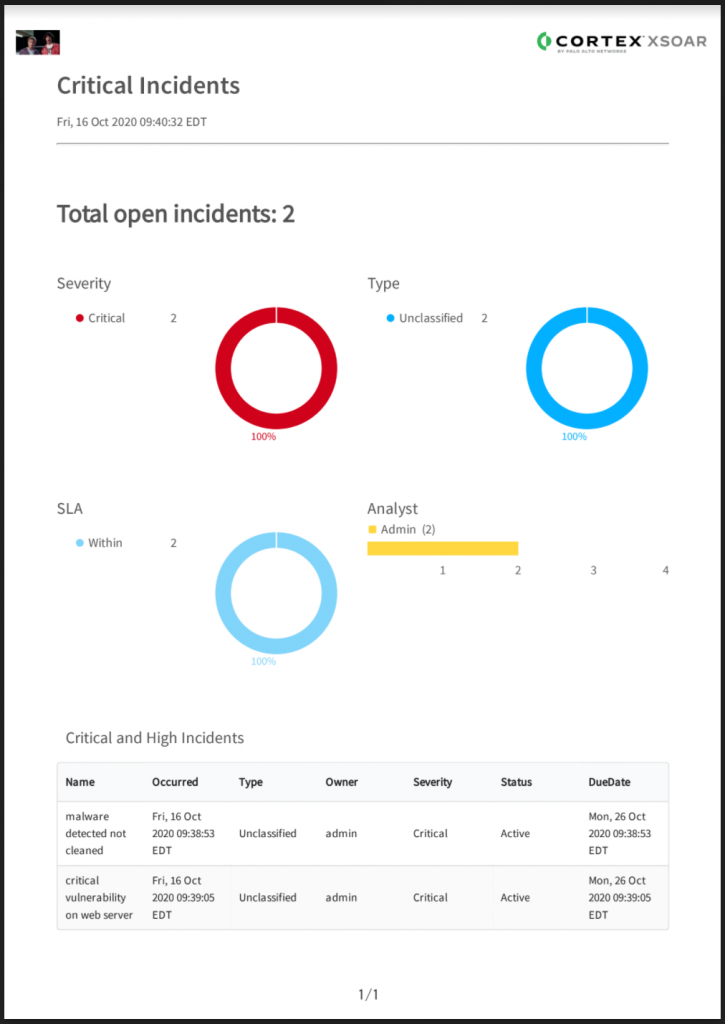
I have no doubt that every SOC has this need but maybe they just don’t know it yet?
My closing advice: always think broader than the two or three incidents you work on regularly or the most annoying cases you work on within the SOC. The business should know the value the SOC brings by thwarting attacks in a timely manner and easily demonstrate your value to the organisation.
Awesome post Patrick I look forward to the your next one 🙂
Andy