PICERL is the SANS 504 acronym for incident handling process, and I how usually suggest customers structure new playbooks.
Mapping common playbook Actions (i.e. API calls) to this we can get a similar alignment:
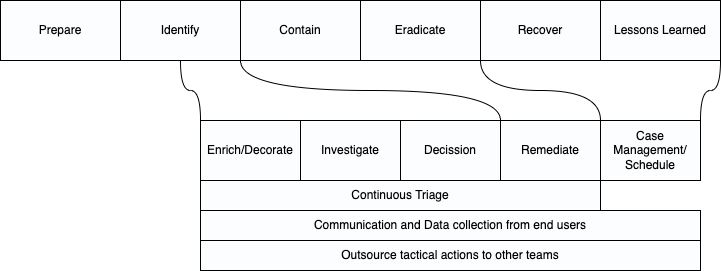
Specialising in SOAR for 3-4 years, the most common playbook Actions per category are:
| Enrich/Decorate | Enrich Users (Active Directory, Google Workspace, AzureAD) Enrich Assets (SQL database, asset management) Enrich IOC (VirusTotal, MISP, etc) Enrich the timeframe of the alert (check SIEM for 10 minute window) Decorate the alert with maps, ASN Send a question to involved user with clickable response Send a question to involved user inviting free form responses Enrich against change requests |
| Investigate | Checking automated enrichments Follow documented processes (minimal viable ticket) Analysing “hunch” work (additional dynamic investigation) Communicate/collaborate with teams |
| Decission | Human decision: true positive / false positive (free cookie if you can categorise as false negative) |
| Remediation | Delete file Quarantine endpoint Reset password/account Block IP/Domain etc |
| Continuous Triage | The playbook (and human analyst) should continuously rescore the alert as the enrichments come in The playbook (and human analyst) reassign according to evidence Reflect case handling stage (and in turn automatically change SLAs) Checking the clock to reassign on shift patterns and/or OOH processes |
| Communications and Data Collection from end users | Send notifications to end users with state changes Send a question to involved user with clickable response Send a question to involved user inviting free form responses |
| Outsource tactical actions | Often smaller tasks are owned by other teams, either through technical limitations (limited licences) or political limitations (only a firewall team can touch the firewall). Using communications we can Deputise vs Delegate these smaller tasks into other ticketing systems, and automatically the playbook will recognise and continue when these have been completed. Searching sensitive mailboxes can only be done by HR? Changes to policies in other business units Rebooting/disconnecting for remote on prem equipment etc |
Taking it further
The SANS cheatsheet (link top) has many actions/ideas I rarely see in deployments, but what could we do?
| Forensics Memory captures | Imagine calling APIs to snapsnot a VM and put that image into a container in cloud compute ready for analysis |
| Recovery Phase | Un-isolating a host then placing it in a partially connected network/vlan for 30 days with stricter controls and auto audit daily checks |
| Enrich from policies | Checking documented policy/process for more Alert insights |
| Training | Imagine using SOAR to trigger Phishing emails to staff then using a playbook to count how long it takes them to report vs a different team. |
Or even further?
Andy