SOAR vendors (including the one I work for) have lots of material on the most common usecases. So today I will write about some of the more interesting and specific use cases I have built in the wild.
In no particular order:
Scheduled Active Directory Sweeps
Every x hours, SOAR search for the members of “OU=DomainAdmin” and compares to the previous result. If someone new is added, SOAR instantly removes them and create a Critical severity incident. If the security team approve, SOAR automatically replaces that member to the OU and resets the benchmark.
Result: Improved monitoring of sensitive roles in AD for unsanctioned accounts.
Impossible traveler
Tweaking the usual playbook but adding an advanced severity calculation, is the user in the OU “travelling engineer”, and is the alert location a data center? If yes just inform their manager for approval.
Result, cut down on false positives.
Leavers process += Release licence entitlement
Automating the leavers process is quite standard for SOAR (revoke in okta, AD, emails, collect hardware, etc).
The interesting twist is to auto release the Office 365 licence utilisation which was always missed before, unfortunately the organisation had a high throughput of freelancers and this was accumulating significant costs.
Result: Direct cost saving.
Alert Decoration
A security team had 4 main tools (NTA, EDR, NIDS, SIEM) and every alert meant they had to swivel chair across 4 platforms for 10 minutes to just understand the alert. SOAR would ingest from any solution, then run 1 playbook that would enrich against everything.
For every alert, 15 seconds after the alert fired they had 1 dashboard with EVERYTHING from everywhere to start investigating.
Result: Enormous time saving across every alert type, quicker time to respond, reduced analyst burnout.
Rapid turnover of tier1 staff
A MSSP SOC in Asia had had a high turnover of staff as employees trained up and quickly moved employment to get a pay rise. This causes problems with retaining a tier1 service.
I built a playbook to walk an ‘inexperienced’ analyst through a long process.
Result: Increased speed, decreased process deviation (and therefore risk), increased accuracy and customer happiness, reduced need for existing staff to babysit the newcomers.
End-to-end Phishing testing
It’s common to use SOAR to investigate phishing, but I heard of a USA customer that actually used SOAR to trigger the phishing emails at random.
This enabled the customer to correlate how many emails were sent out with how many were reported. This simplified trend analysis, tracking different departments, effectiveness of training, recipient resposne times, etc.
Result: Much tighter end to end Phishing training.
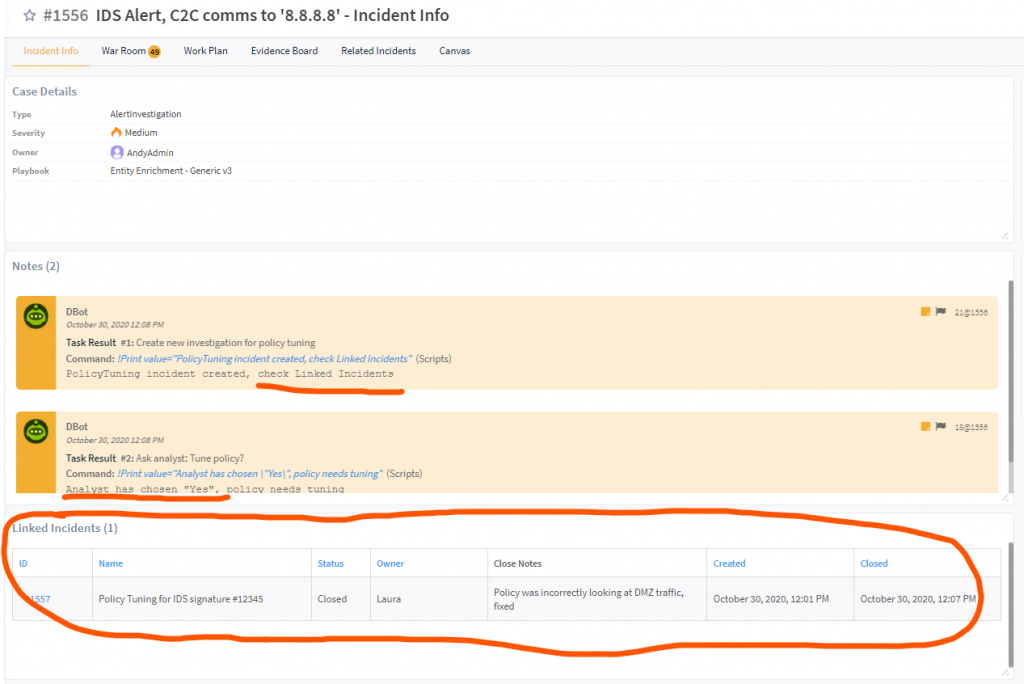
Deputise allowList approval process (and tidyup)
Using SOAR manage Allow/Exemption lists is common. For this usecase my customer wanted to deputise the approval process to the employee’s manager (we could find this querying the user in ActiveDirectory).
This approach removes the security team bottleneck and resulted in much quicker incident turn around time (everyone becomes happier). And whilst the end users (and their managers) own the process, they don’t actually have access to anything.
The other twist was that the playbook would tidyup and remove the rule after 7 days to keep things tidy.
Result: Quicker turnaround time for change requests, and auto tidy up to reduce long term risk.
Enrich existing ticketing systems with generic IT info
Any end users can create incidents in Jira/SNOW. SOAR scrapes these API for specific ticket types, pulls in every the ticket details (IP, hostname, AD username, Domain, etc) then enriches all findings against internal sources and threat intel and pushes back to the same ticket.
This gives instant added context to all tickets to all staff with no effort.
A stretch goal on this playbook could be to notify system owners when their systems are being talked about?
Results: Constant 24/7 automatic ticket enrichment supporting the whole business.
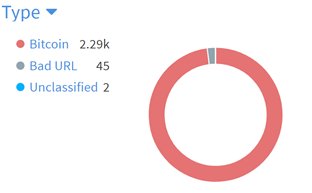
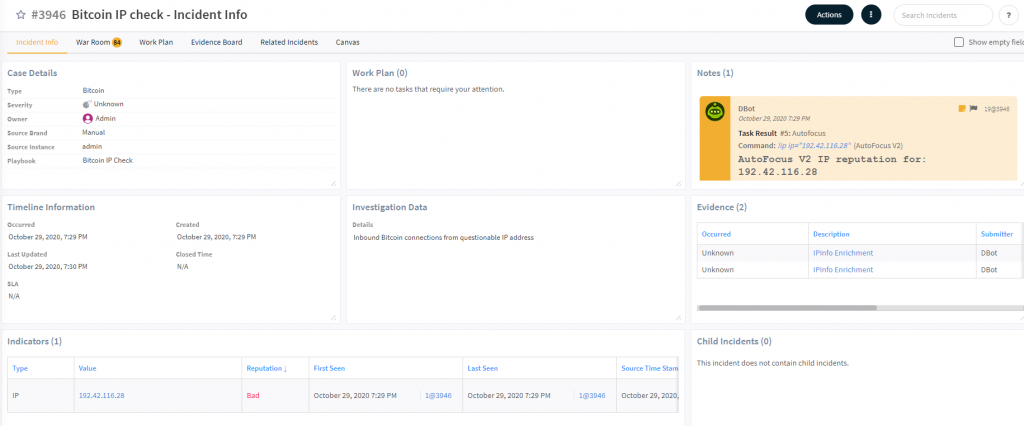
Typosquatting Domains
Here SOAR receives a daily alert from RecordedFuture on “newly registered domains that contain your corporate name”. Each new Domain was a separate SOAR incident, which collected screenshots, threat intelligence, whois, and much more straight into the TIP
Every Domain is then presented to an analyst as a 1 page executive summary allowing the team to simply decide “false positive, confirmed phishing, block in the firewall, report to Lawyers, rescan in 24 hours” etc.
Results: Increased audit history, trend analysis, and the entire existing daily process was lowered from several hours to 15 minutes.
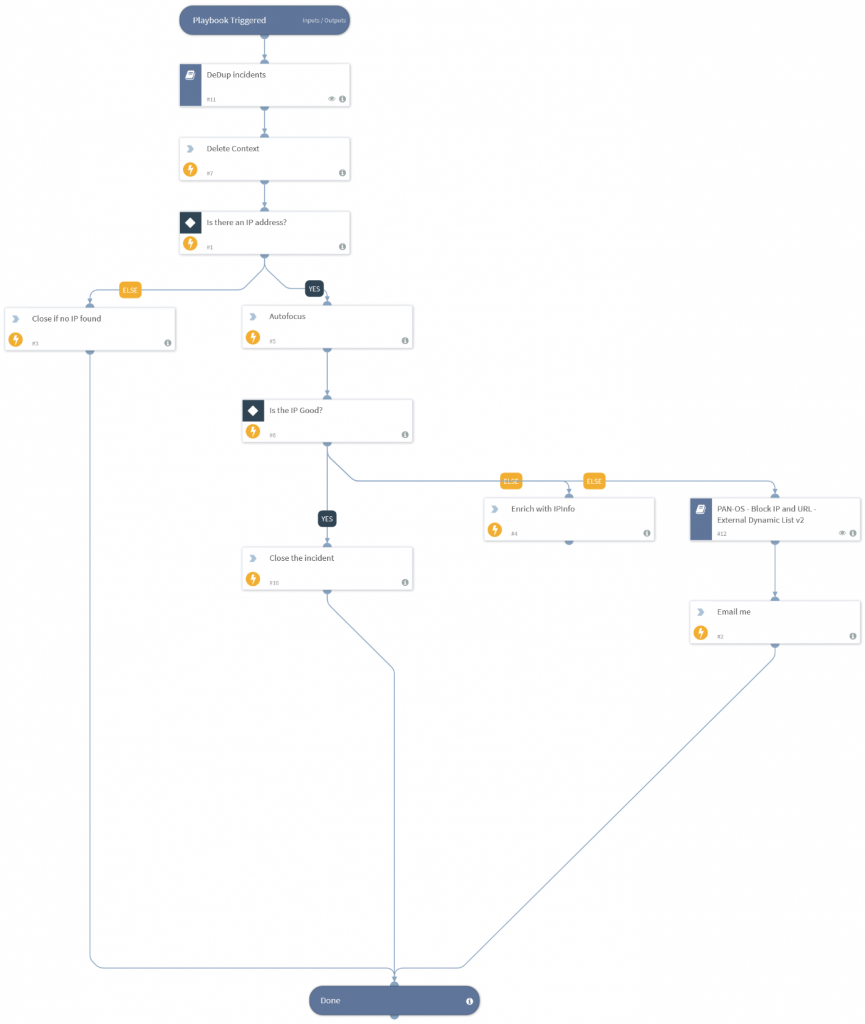
Misconfigured Cloud Infrastructure
Stealthwatch would report on cloud instances with weak configs. The SOAR process would ingest the alert, correlate the machine name with asset management to find the system owner and email them asking them to either i) fix the mistake ii) approve the unexpected config.
The cloud instance was then rescanned and the Security team would approve the end user decision.
Results: Massive time saving, increased audit log of who approved any actions (reducing political risk to Security team).
Deobfuscate PowerShell
Customer received numerous alerts from EDR of obfuscated Powershell. SOAR playbook would ingest the alert, process the entire process tree (process name, PIDs etc), find all PowerShell commands, Base64 decode, pass strings through powershell deobfuscator, then perform IOC extraction and enrichment.
The entire incident was presented to the analyst to check over to decide if the command was innocent or ‘interesting’ and required further investigating.
Result: Big time saving of a very tedious process
Highly sensitive network – Managing alerts
A highly sensitive network with almost no access to the corporate network. When an alert was raised in the sensitive network SOAR was used to pull in all alerts, enrichment, logs, correlation etc. This ‘case study’ was converted into a report, zipped, then queue for scheduled (and heavily scrutinized) upload out of the sensitive network to the security team to investigate.
Result: Simpler process and much faster time to investigate whilst still complying with internal process
PDF Threat Report -> Microsoft Defender syntax
A security team received many cyber threat reports full of IOCs, they had to extract all IOC from the report and convert these into a very specific “Windows Defender” query syntax to initiate a network wide scan.
The SOAR playbook we built scanned the PDF, extracted every IOC and formatted them into Microsoft Defender syntax and sent the command to the network team over Slack to initiate the scan. The network team could then reply with different options to trigger different responses in the security team.
Results: Fewer missed IOC, much quicker turnaround on hunting
Validating service account usage
Members of IT staff were permitted to use service accounts, but validating/auditing each privilege escalation against the source user was a big burden on the SOC team.
A SOAR playbook was created to watch for a svc account usage/priv escalation, then enrich the log to find the employee, and finally sent them a simple yes/no question. If the end user acknowledged within 24 hours the ticket was closed, if they denied it or failed to respond in time the ticket was escalated to the SOC team to investigate further.
Result: A vital security control now takes no effort to perform and they have a completely automatic with dashboards, escalation process, etc.
Daily infrastructure testing, lots of devices
1000+ WAP and every day some crash. Solution: Ingest the device statuses from Aruba, then for each WAP identify the physical site location and which floor the WAP is on. Then identify asset owner, log a ticket in SNOW, assign to the right team etc.
Taking it forward we discussed the ability for SOAR to know if the onsite staff would need documents/help (e.g. if WAP was hidden in roof)
MSSP, reviewing user lock outs
Automate alert enrichment against the alert and the rest of the business. In addition SOAR enrichment would validate:
- Many alerts against one account on one box? Likely an attack
- Few alerts on different boxes, likely false positive
- Many alerts on many boxes = password spraying
Result: Time saving (and improved service). Some customers were facing 125 lockouts in 3 days, so this adds up quickly.
MSSP: Managing IOC to EDR
Every bad inbound IOC detection needs pushing to EDR tenants, and whilst some tenants are happy with auto blocking, some are not.
We built a playbook that can enriches each tenant (against SNOW etc) to find which customer has which accepted risk profiles to push IOC automatically to the customers that allow it, but then prompt an analyst for the tenants that don’t.
Result: streamlined process, quicker time to block, improved security service.
Where do I stop, I could go on for days! But I hope this encouraged a little imagination 🙂
Andy