After recently getting married, I quickly discovered my wife was cheating on me, with these three:
As soon as I left the house to go shopping, seeing the family, or working away my (NOT-SO-)good lady would jump into bed, turn on the TV and spend quality time watching series without me, getting ahead in a series we were watching together !
This is disastrous and would no doubt lead to a playbook on how get divorced. Urgent actions were needed, so I turned to SOAR!!
(Really this is a blog post about automating the whitelisting/blacklisting of IP/domains. Either for a SOC team who are detecting new attacks, or whether it’s members of staff managing their own policies. But hey I love drama, pun intended. Read to the end where I discuss “This In Business”)
I need a process that:
- Automatically detects this activity
- Automatically remediates this activity
- Validate if I’m home
- Communicates with the culprit (played by my hussy wife)
- Seeks confirmation from sysadmin (in this post the victim is played by the flawless handsome and honorable me)
- Audit logs, SLA, etc
Setup
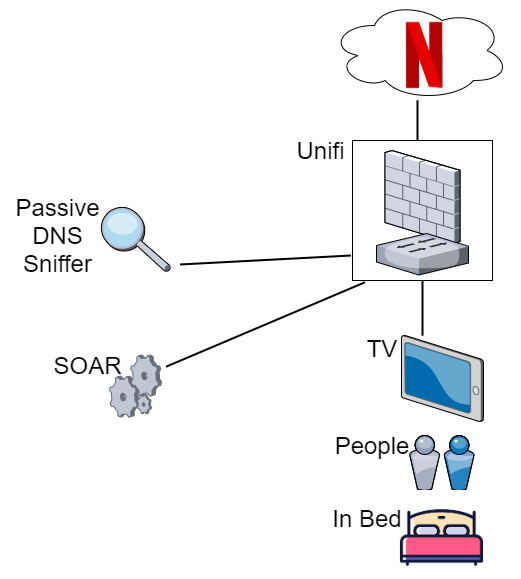
SOAR running on a virtual machine at home
The DNS activity/alert is generated by PassiveDNS on a Raspberry PI on a network sniffer port
My home network has lots of Unifi in. Unifi do amazing kit with a full API available to control the WAP, Firewall rules, network config etc. I <3 the Unifi!
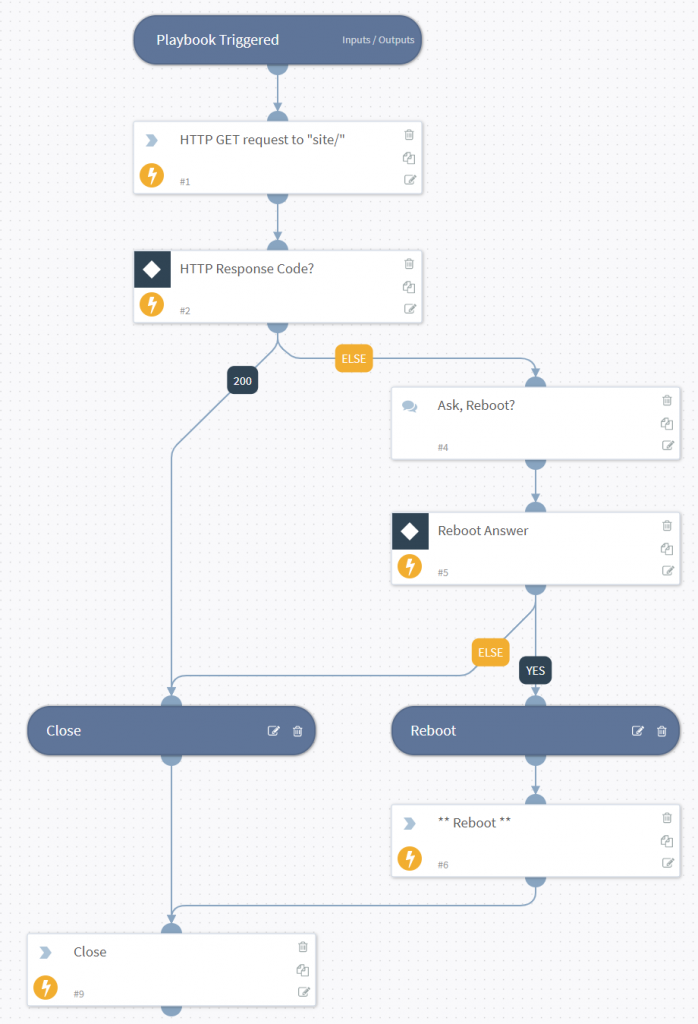
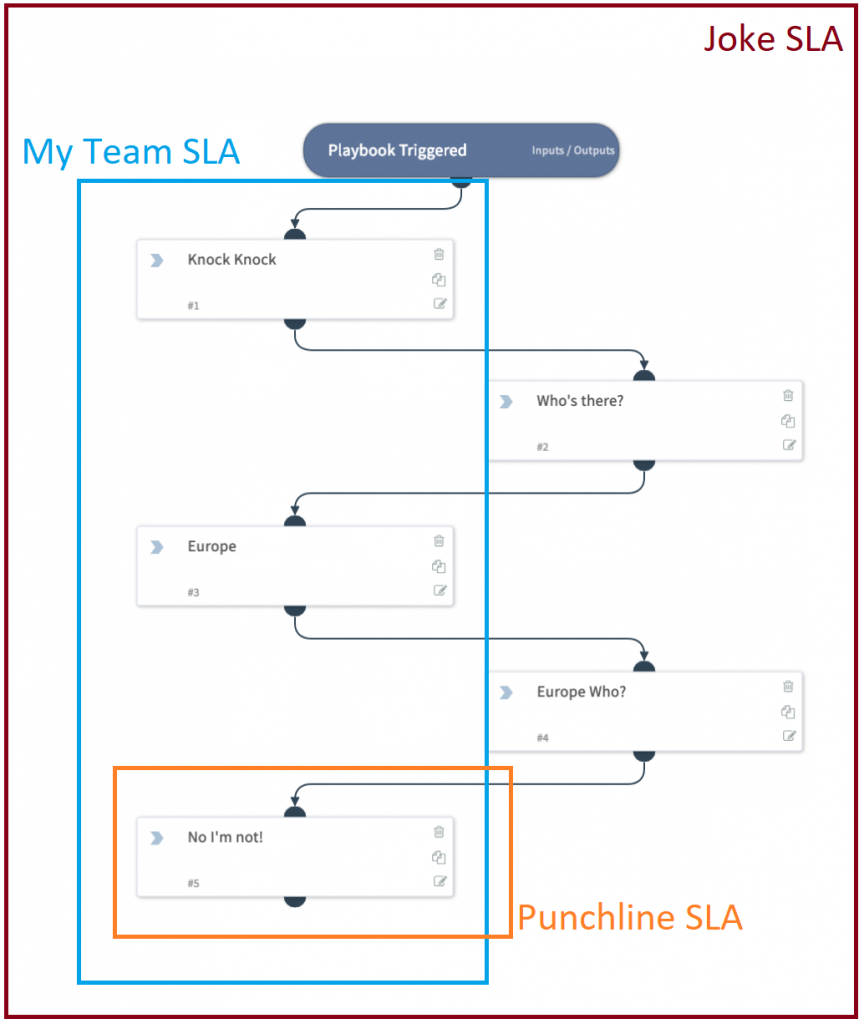
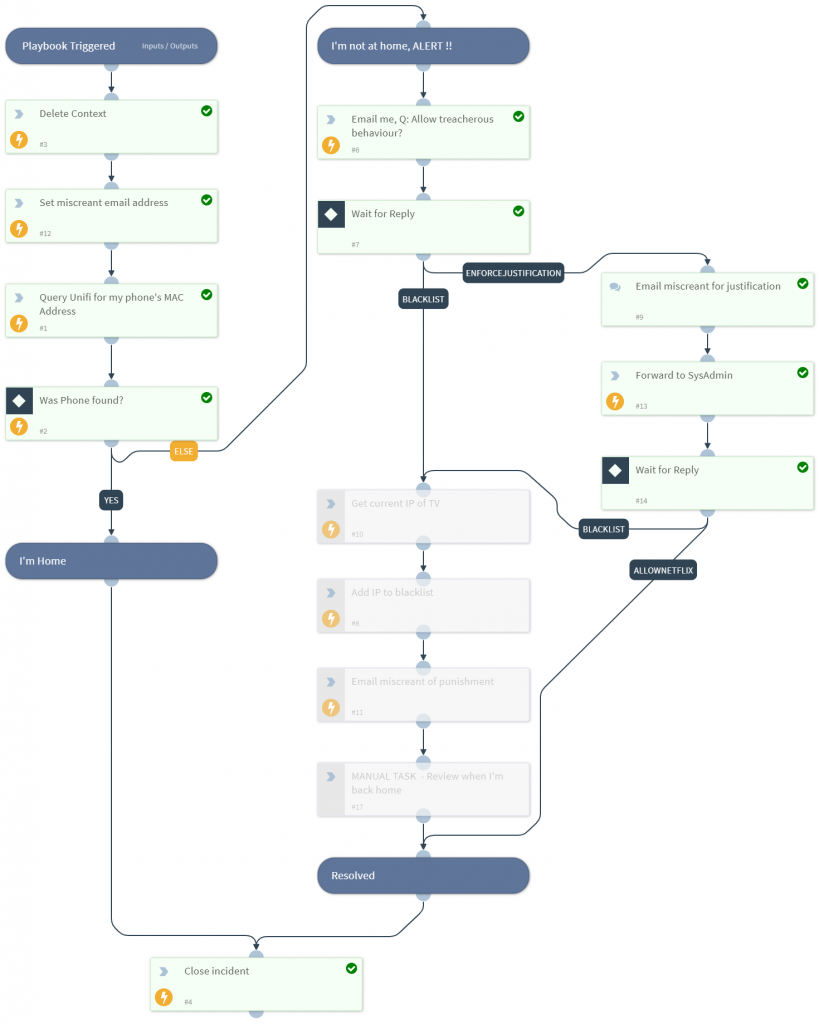
Workflow Process
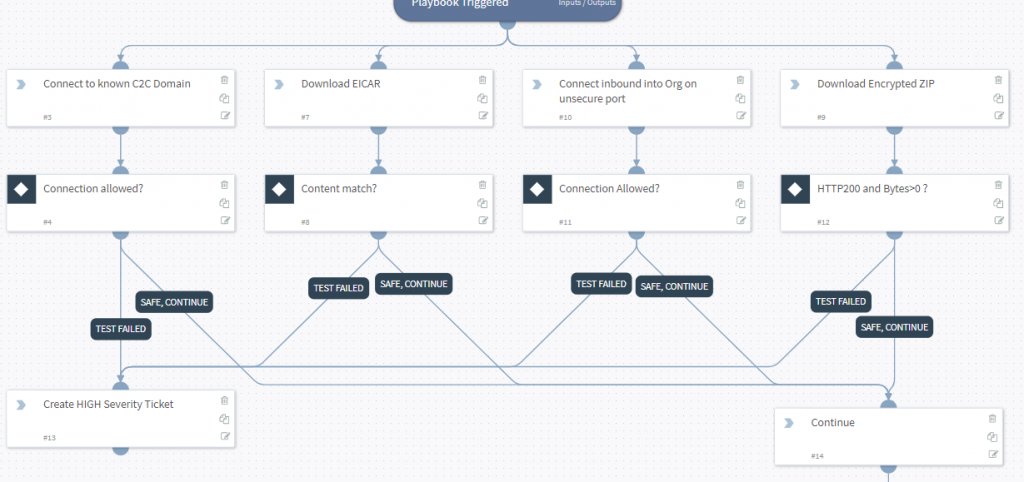
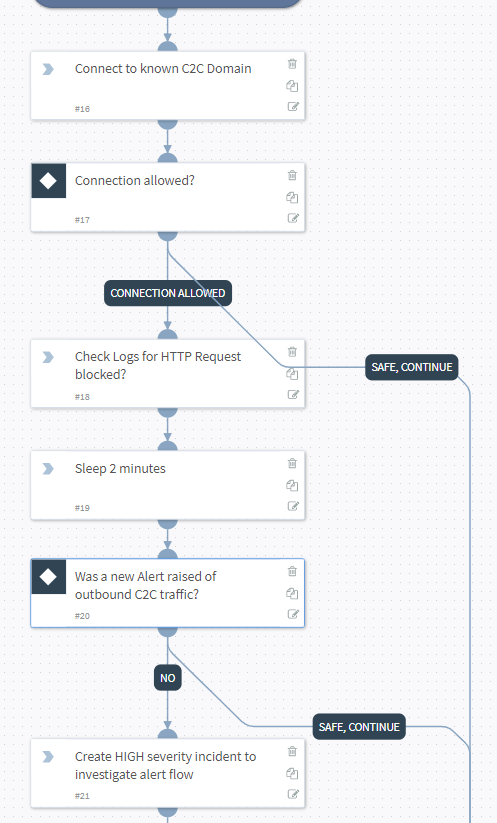
To avoid a SIEM at home, I simply have PassiveDNS forward logs for Netflix DNS requests direct to SOAR.
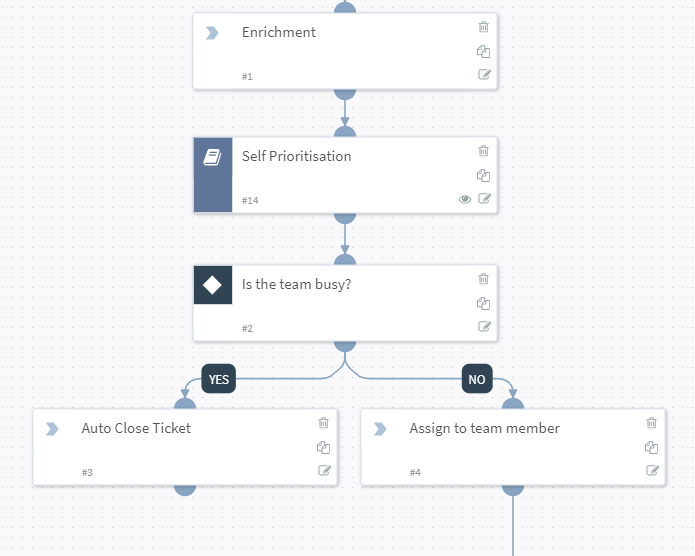
PreProcessing is then used to make sure that all prior tickets/incidents are closed (i.e. check this is a new situation)
SOAR then queries my Unifi controller to see if my personal mobile phone is connected to the WIFI. If “yes” then I am home, if “no” I’m likely out travelling.
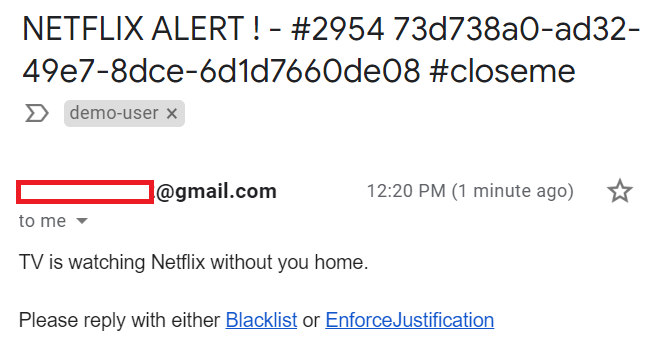
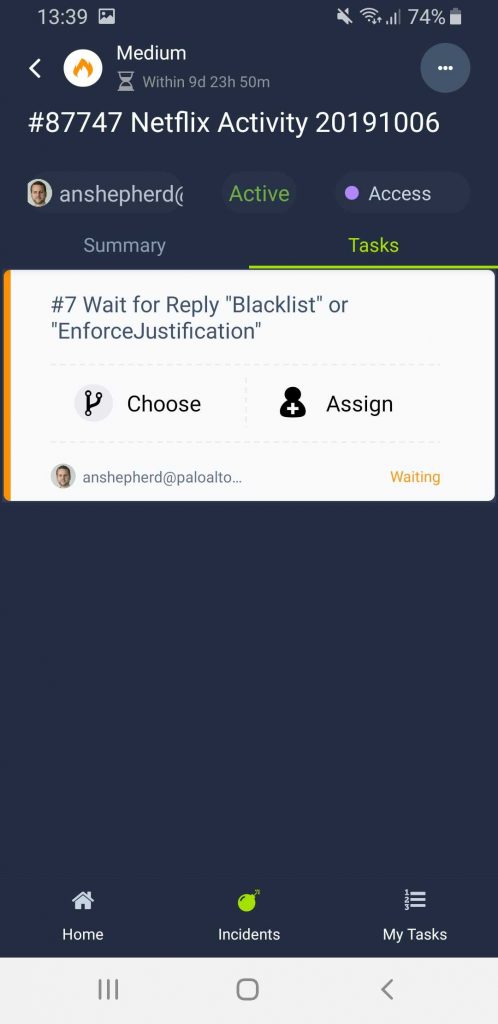
The VICTIM (innocent me) who is likely in a hotel/shop is then either sent an email with a choice to block the activity instantly, or to request a justification….
….or if I’m being an uber admin, I can use the mobile app to decide….
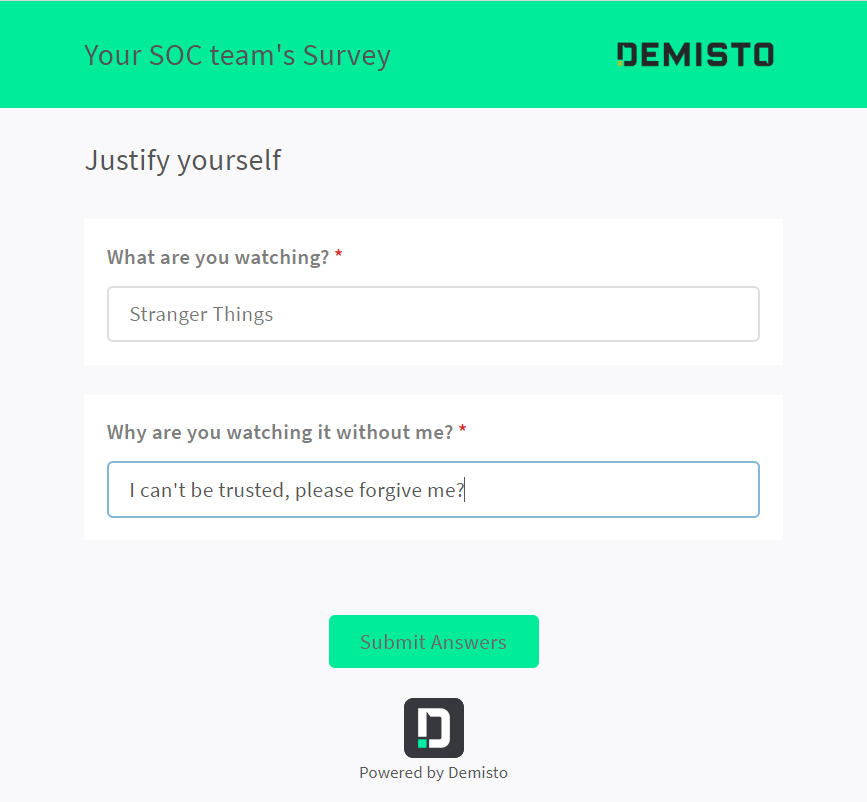
If I chose to ask “EnforceJustification” a questionnaire is send to the wicked one!
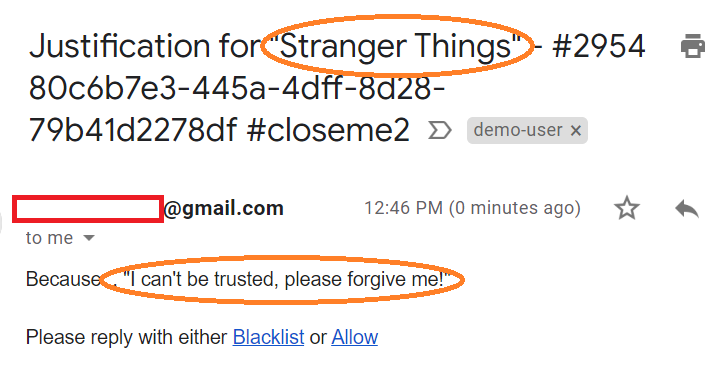
Answers are forwarded to the sysadmin
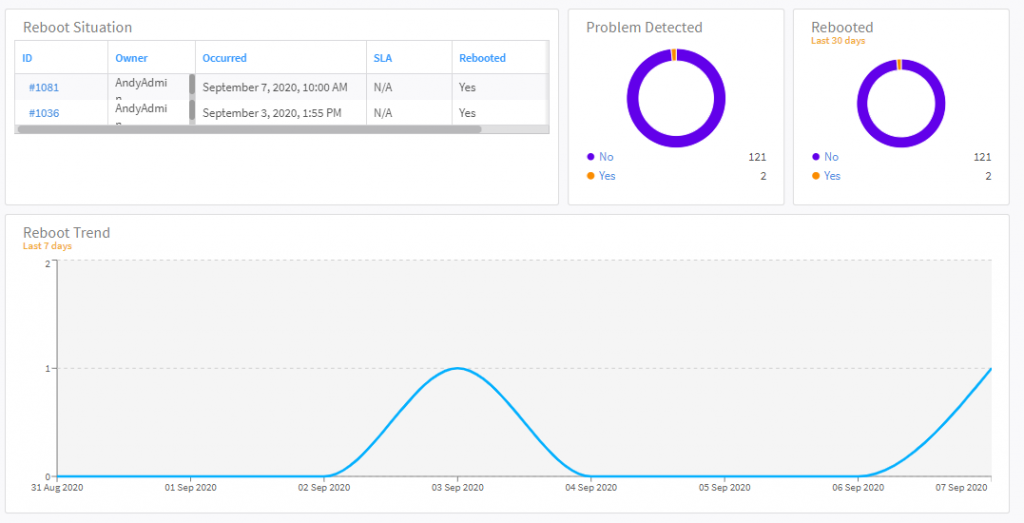
Of course being the benevolent kind generous soul I am, I of course decide to Allow this traffic (between you and me, I watched this the other day, so I’m already ahead of her… #guilty)
And thus our marriage is saved. Should I train to become a marriage counsellor?
SOAR Value Realised
I previously talked about the value of SOAR and I think this playbook ticks off many of those:
- Reduce alert overhead
- Quicker to act
- Standardise your workflow
- Standardise approvals
- Revitalise legacy/simple tools
This In Business
Many of us are familiar with this phone call from a member of staff who was denied a work related website:
“How dare you block my access to the internet, I need that website to do my job! You’re stopping business! Stop being paranoid! I’m going to report this!”
So let’s adapt the above process:
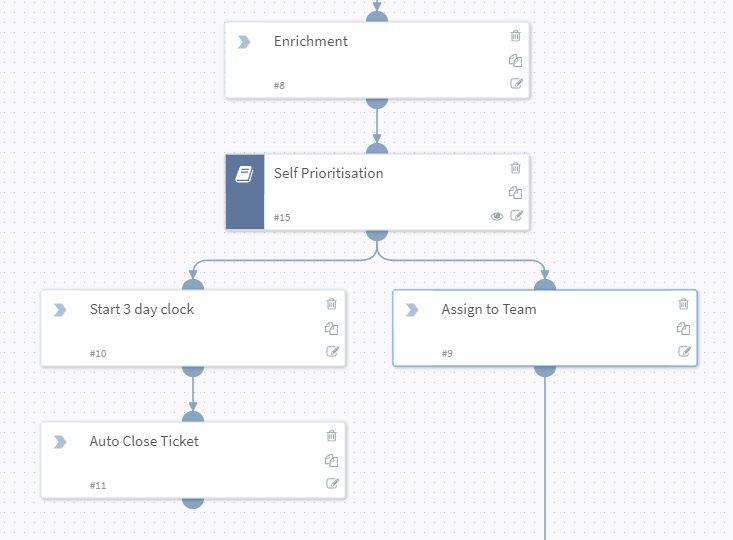
- A workflow initiated by the end user (through a ticketing system, SIEM, emails, or other)
- Playbook asks the user which domain to whitelist, for how long, and for what justification
- Playbook then checks if this domain was requested before. If denied, ticket can be closed. If approved a few times should we consider a long term whitelist?
- Playbook then enriches the domain against Threat Intel: Is it known malicious, is it less than a week old, is it an inappropriate category of site
- Playbook enriches with ActiveDirectory to determine that users manager
- Playbook emails manager for approval with all the details and buttons of “yes approve” or “no, block”
- If the manager approves the domain is whitelisted
- And after the correct amount of time, automatically removes the policy change to clean up.
We now have a process that is operational 24/7, works at the speed of the affected staff (not the huge workload of the security team), takes no effort on your team, does threat enrichment and sanity checking, cleans up after itself, has SLA, RBAC, is fully audited. All the while, no member of staff was given access to any security tool!
Useful ?
Andy